Lab 12: SQL
Due at 11:59:59 pm on 12/07/2021.
Starter Files
Download lab12.zip. Inside the archive, you will find starter files for the questions in this lab, along with a copy of the OK autograder.
Submission
By the end of this lab, you should have submitted the lab with python3 ok --submit. You may submit more than once before the deadline; only the final submission will be graded. Check that you have successfully submitted your code on okpy.org. See this article for more instructions on okpy and submitting assignments.
- To receive credit for this lab, you must complete Questions 1 and 2 (Question 3 is optional) in lab12.sql and submit through OK.
SQL Basics
Creating Tables
You can create SQL tables either from scratch or from existing tables.
The following statement creates a table by specifying column names and values
without referencing another table. Each SELECT clause specifies the values
for one row, and UNION is used to join rows together. The AS clauses give a
name to each column; it need not be repeated in subsequent rows after the
first.
CREATE TABLE [table_name] AS
SELECT [val1] AS [column1], [val2] AS [column2], ... UNION
SELECT [val3] , [val4] , ... UNION
SELECT [val5] , [val6] , ...;Let's say we want to make the following table called big_game which records
the scores for the Big Game each year. This table has three columns:
berkeley, stanford, and year.
We could do so with the following CREATE TABLE statement:
CREATE TABLE big_game AS
SELECT 30 AS berkeley, 7 AS stanford, 2002 AS year UNION
SELECT 28, 16, 2003 UNION
SELECT 17, 38, 2014;Selecting From Tables
More commonly, we will create new tables by selecting specific columns that we
want from existing tables by using a SELECT statement as follows:
SELECT [columns] FROM [tables] WHERE [condition] ORDER BY [columns] LIMIT [limit];Let's break down this statement:
SELECT [columns]tells SQL that we want to include the given columns in our output table;[columns]is a comma-separated list of column names, and*can be used to select all columnsFROM [table]tells SQL that the columns we want to select are from the given tableWHERE [condition]filters the output table by only including rows whose values satisfy the given[condition], a boolean expressionORDER BY [columns]orders the rows in the output table by the given comma-separated list of columnsLIMIT [limit]limits the number of rows in the output table by the integer[limit]
Note: We capitalize SQL keywords purely because of style convention. It makes queries much easier to read, though they will still work if you don't capitalize keywords.
Here are some examples:
Select all of Berkeley's scores from the big_game table, but only include
scores from years past 2002:
sqlite> SELECT berkeley FROM big_game WHERE year > 2002;
28
17Select the scores for both schools in years that Berkeley won:
sqlite> SELECT berkeley, stanford FROM big_game WHERE berkeley > stanford;
30|7
28|16Select the years that Stanford scored more than 15 points:
sqlite> SELECT year FROM big_game WHERE stanford > 15;
2003
2014SQL operators
Expressions in the SELECT, WHERE, and ORDER BY clauses can contain
one or more of the following operators:
- comparison operators:
=,>,<,<=,>=,<>or!=("not equal") - boolean operators:
AND,OR - arithmetic operators:
+,-,*,/ - concatenation operator:
||
Here are some examples:
Output the ratio of Berkeley's score to Stanford's score each year:
sqlite> select berkeley * 1.0 / stanford from big_game;
0.447368421052632
1.75
4.28571428571429Output the sum of scores in years where both teams scored over 10 points:
sqlite> select berkeley + stanford from big_game where berkeley > 10 and stanford > 10;
55
44Output a table with a single column and single row containing the value "hello world":
sqlite> SELECT "hello" || " " || "world";
hello worldJoins
We can use joins to include rows from another table that satisfy the where
predicate. Joins can either be on different tables, or the same table if we
include an alias. Here we are referencing the football table twice, once as
the alias a and once as the alias b.
sqlite> SELECT a.Berkeley - b.Berkeley, a.Stanford - b.Stanford, a.Year, b.Year
...> FROM Football as a, Football as b WHERE a.Year > b.Year;
-11|22|2014|2003
-13|21|2014|2002
-2|9|2003|2002What is this query asking for?
You may notice that it does not seem like we actually performed any operations
to do the join. However, the join is implicit in the fact that we listed more
than one table after the FROM. In this example, we joined the table Football
with itself and gave each instance of the table an alias, a and b so that
we could distinctly refer to each table's attributes and perform selections and
comparisons on them, such as a.Year > b.Year.
One way to think of a join is that it produces a cross-product between the two tables by matching each row from the first table with every other row in the second table, which creates a new, larger joined table.
Here's an illustration of what happened in the joining process during the above query.
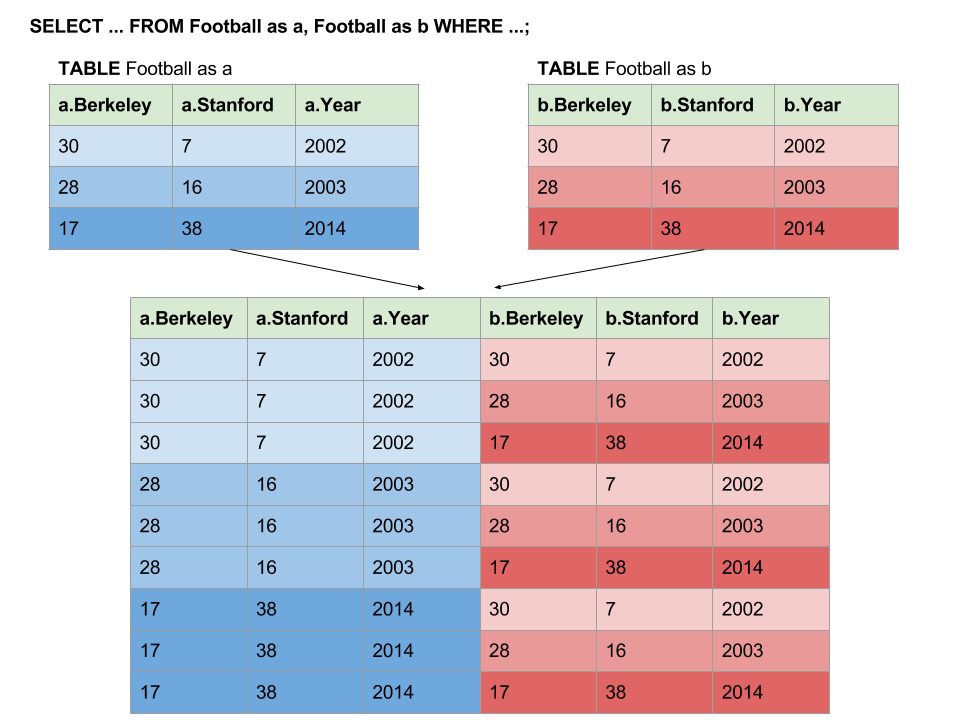
From here, the select statement examines the joined table and selects the values
it desires: a.Berkeley - b.Berkeley and a.Stanford - b.Stanford but only
from the rows WHERE a.Year > b.Year. This prevents duplicate results from
appearing in our output!
Cafe
A block of 10 store locations, numbered 1 through 10, already has some cafes. Cafes can serve espresso, bagels, coffee, muffins, and eggs (but nothing else).
-- Locations of each cafe
create table cafes as
select "nefeli" as name, 2 as location union
select "brewed" , 8 union
select "hummingbird" , 6;
-- Menu items at each cafe
create table menus as
select "nefeli" as cafe, "espresso" as item union
select "nefeli" , "bagels" union
select "brewed" , "coffee" union
select "brewed" , "bagels" union
select "brewed" , "muffins" union
select "hummingbird" , "muffins" union
select "hummingbird" , "eggs";
-- All locations on the block
create table locations as
with locations(n) as (
select 1 union
select n+1 from locations where n < 10
)
select * from locations;Question 1: Open
You would like to open a new cafe. Create a table open_locations that
has a single column n where each row is a location that is not already
occupied by an existing cafe.
-- Locations without a cafe
create table open_locations as
-- REPLACE THIS LINE
select n from locations, cafes group by n having min(abs(n-location)) > 0;
-- select * from open_locations where n >= 5;
-- Expected output:
-- 5
-- 7
-- 9
-- 10Hint: Join
locationsandcafesin thefromclause, so that you can compare a locationnwith thelocationof an existing cafe.Hint: A location is open if its minimum distance from an existing cafe is more than 0. The built-in
absandminfunctions can be used to express this condition in ahavingclause.
You can test your solution interactively using sqlite3 by comparing with the expected output above.
$ sqlite3 -init lab12.sql
sqlite3> SELECT * FROM open_locations WHERE n >= 5;You can also test your solution using ok:
python3 ok -q openQuestion 2: Allowed
To limit competition, the block mandates that no cafe can have a menu item that is sold by another cafe within 2 locations. So, if location 2 already sells bagels, then a cafe located at 1, 3, or 4 cannot sell bagels. You may assume that every item is sold by at least one cafe.
Create a table allowed that has two columns, a location n and a menu
item. The rows should contain every item that can be sold at every
location, based on these constraints. It should include occupied
locations that could expand their current menus.
-- Items that could be placed on a menu at an open location
create table allowed as
with item_locations(item, location) as (
select item, location from cafes, menus where name = cafe
)
-- REPLACE THIS LINE
select n, item from locations, item_locations
group by n, item having min(abs(n-location)) > 2;
-- select * from allowed where n >= 5;
-- Expected output:
-- 5|bagels
-- 5|coffee
-- 5|espresso
-- 6|espresso
-- 7|espresso
-- 8|espresso
-- 9|eggs
-- 9|espresso
-- 10|eggs
-- 10|espressoHint: Join locations and item_locations, so that you can compare how
far a location n is from the location at which an item is already sold.
Hint: Group by a combination of the location
nand theitemthat might be sold atn; use ahavingclause to filter the groups.Hint: You do not need to use
open_locationsfrom the previous question.
You can test your solution interactively using sqlite3 by comparing with the expected output above.
$ sqlite3 -init lab12.sql
sqlite3> SELECT * FROM allowed WHERE n >= 5;You can also test your solution using ok:
python3 ok -q allowedQuestion 3: extra
This question is optional and ungraded. It is definitely a challenge question! You will need to answer the previous two questions successfully to answer this question.
You decide you will sell as many menu items as possible in your new location.
Create a table full that has three columns, an open location n, a
comma-separated list of items that you would sell, and the length of that
list. The items should be in alphabetical order, and only the longest
possible list of items for each location should appear as a row.
-- Open locations and their maximum-length menus
create table full as
-- REPLACE THIS LINE
with open_allowed(n, item) as (
select a.n, a.item from allowed as a, open_locations as b where a.n = b.n
),
options(location, items, last, k) as (
select n, item, item, 1 from open_allowed union
select n, items || ", " || item, item, k+1 from allowed, options
where item > last and n = location
)
select location as n, items, max(k) from options group by location;
-- select n, items from full where n >= 5;
-- Expected output:
-- 5|bagels, coffee, espresso
-- 7|espresso
-- 9|eggs, espresso
-- 10|eggs, espressoYou can test your solution interactively using sqlite3 by comparing with the expected output above.
$ sqlite3 -init lab12.sql
sqlite3> SELECT n, items FROM full WHERE n >= 5;You can also test your solution using ok:
python3 ok -q fullSubmit
Make sure to submit this assignment by running:
python3 ok --submit